
XSS小记
浏览器渲染过程和解码顺序
参考文章
https://erzbir.com/archives/browser-parsing-xss-tutorail
https://www.secpulse.com/archives/118040.html
https://lalajun.github.io/2018/08/25/%E6%B5%8F%E8%A7%88%E5%99%A8%E6%B8%B2%E6%9F%93%E5%8E%9F%E7%90%86%E4%B8%8E%E7%BC%96%E7%A0%81%E8%A7%A3%E7%A0%81/
常常因为一些Bypass的方式引起困扰,一般抵御XSS的方式都是实体编码,但是为什么有些实体编码的方式也可以出发XSS,例如:<a href=javascript:alert("xss")>test</a>

在href属性中的值显然被解码了,但是还有一种情况:
<div><img src=1 onerror=alert(123);></div>
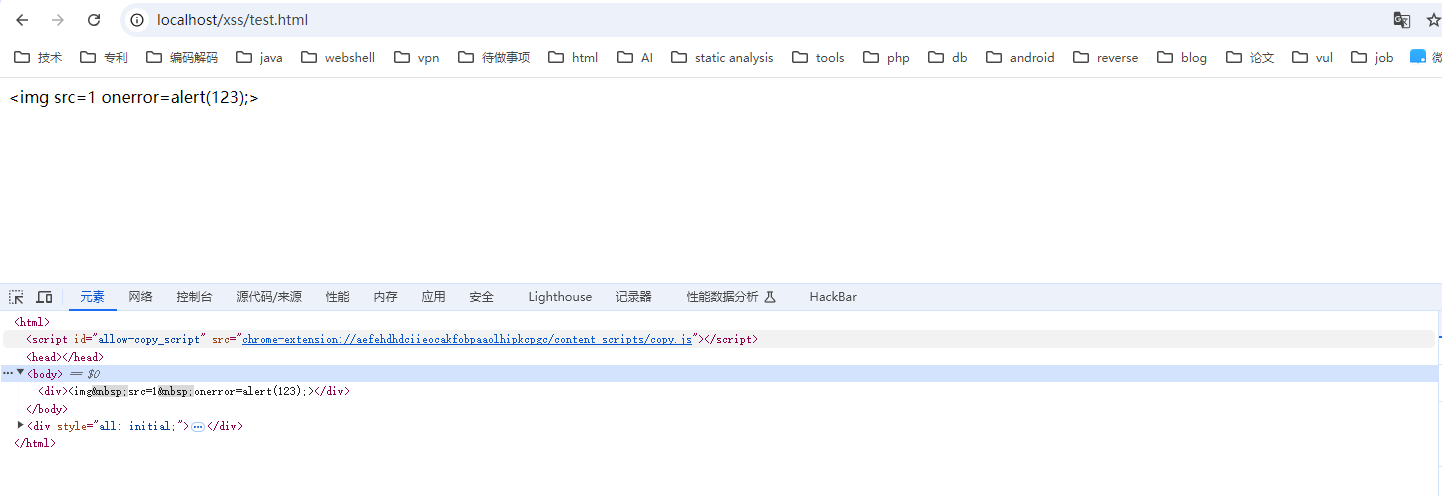
并不会触发XSS,是不是只有在属性中才能用html解码?解析的顺序是什么?
简单介绍一下浏览器的渲染过程
- 处理 HTML 并构建 dom树。
- 处理 CSS 构建 CSSOM 树。
- 将 dom与 CSSOM 合并成一个渲染树。
- 根据渲染树来布局,计算每个节点的位置。
- 调用 GPU 绘制,合成图层,显示在屏幕上。
上述的过程就是大致的浏览器渲染过程,我们着重关注解析HTML构建dom树的过程,下面会用几个例子说明一些上面遇到的问题。
先说结论
- 浏览器在对HTML文档进行解析构建dom树时并不会先对html实体进行解码
- 浏览器的解码顺序是HTML解码 -> URL解码 -> JS解析,这里一定注意并不是所有地方都会进行URL解码、JS解析,而且HTML解码是在dom树构建之后的这一点非常重要
- JS解析会对Unicode编码的字符进行解码
针对上述结论会一一给出具体例子进行验证:
创建dom树时不会对html实体进行解析
浏览器会根据HTML文档构建dom树,什么是dom树呢?
1 | <html> |
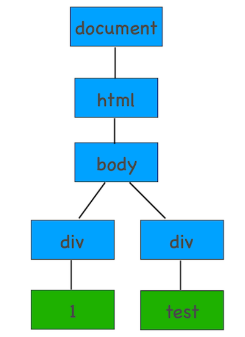
上图就是根据给出的html文档进行构建的dom树,当浏览器解析引擎遇到<html>时会创建html dom节点(将html压入栈中),遇到下一个<body>则将body dom节点加到html节点下(将body压入栈中),然后一步步解析,如果遇到</body>则意味着body dom节点下已经没有节点了(将body从栈中弹出,之后将html弹出栈),所有节点解析完毕则返回dom树(栈中没有元素)。
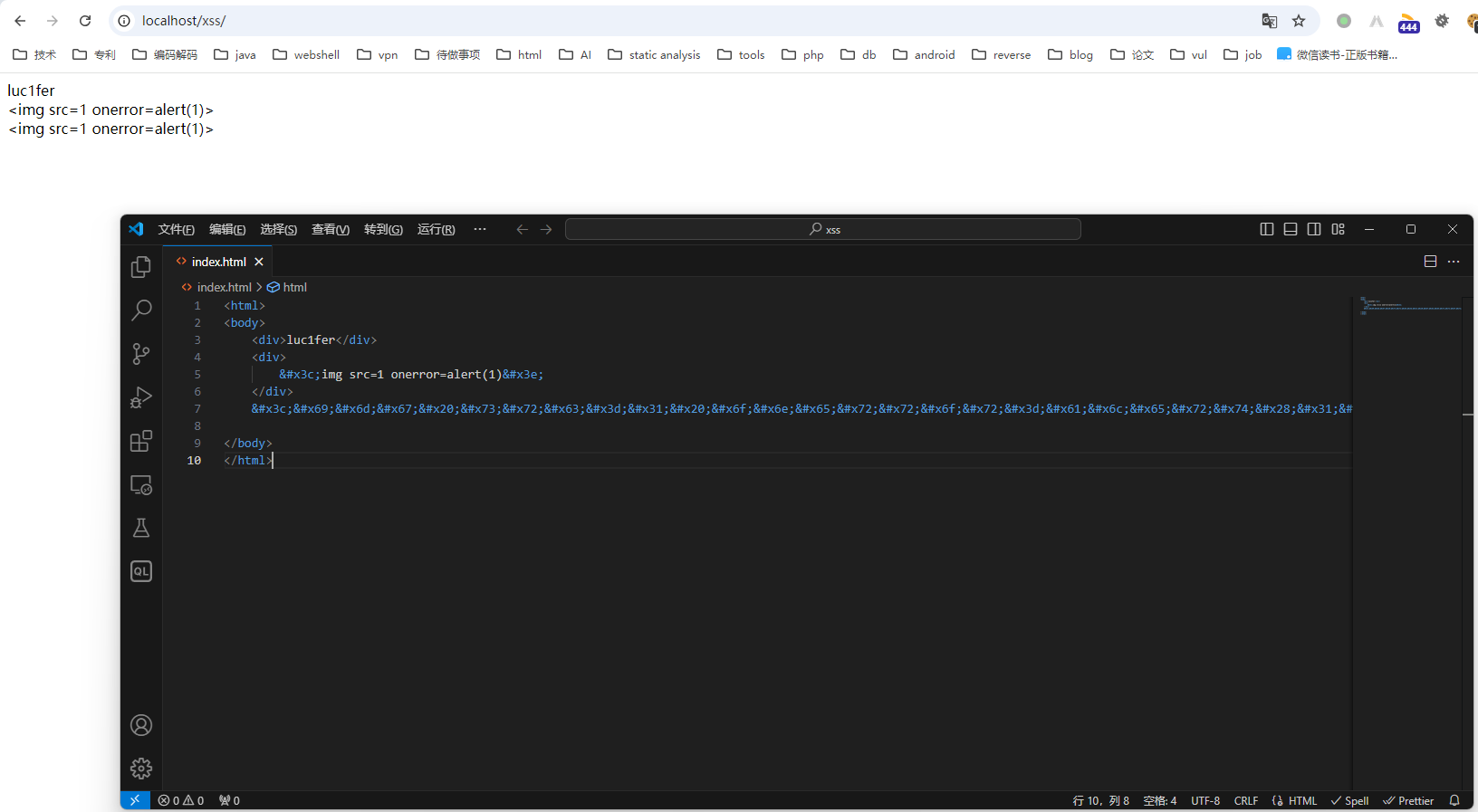
如果在创建dom树时会对实体解码则会创建img dom节点,说明在创建dom树的时候不会对html实体进行解码,只有遇到<才会创建对应标签的dom节点,遇到<会当作div标签的数据内容。
同时标签里的内容存在html实体编码也无法解码,<h1>Main Title会解析为body标签的文本内容。
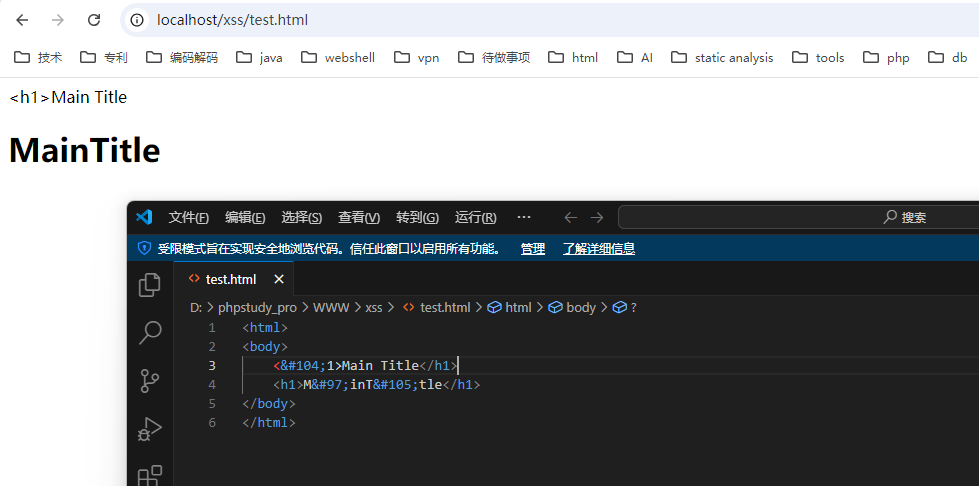
为什么是这样呢?在HTML标准中规定了如上内容。
浏览器引擎解析状态机
<img src=xxxx>
在浏览器引擎对html文档进行解析的时候,遇到<会进入一个tag open state](https://html.spec.whatwg.org/multipage/parsing.html#tag-open-state)状态,对下一个字符进行匹配,如果是ascii字符则会将其匹配为标签名字,对于上面的例子就是匹配到`img`。
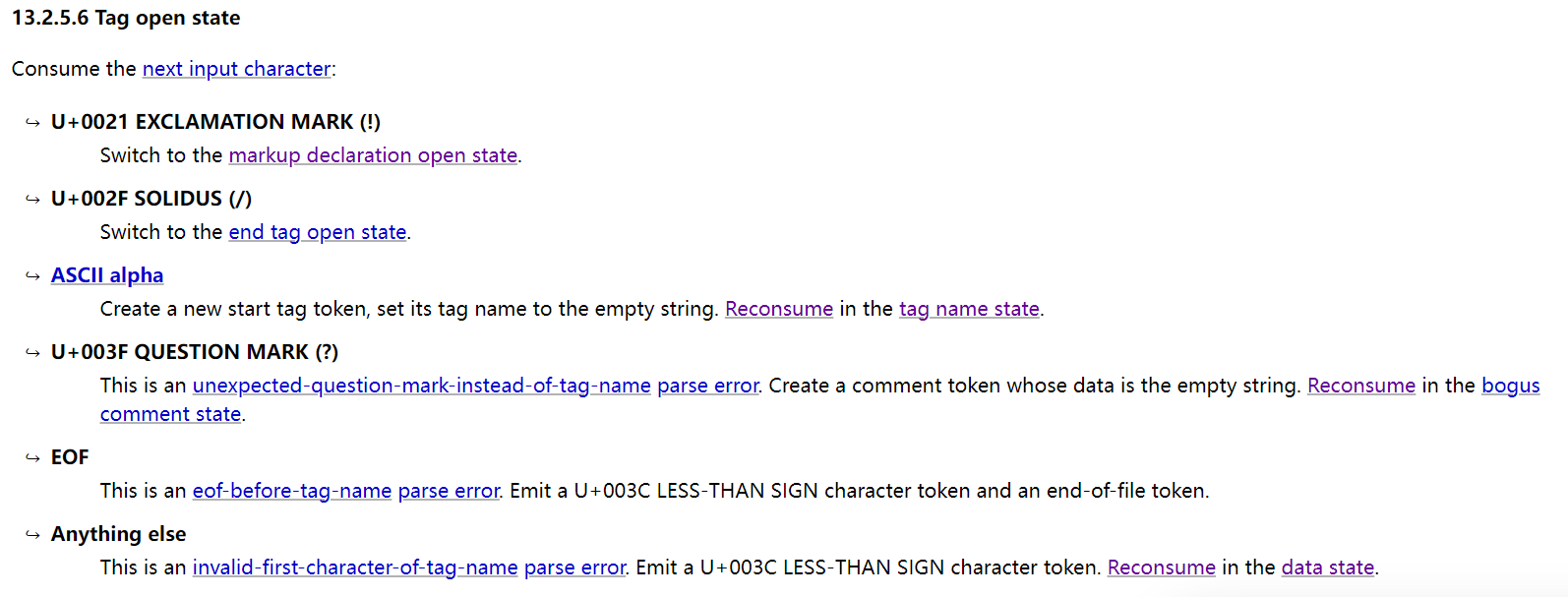
之后会进入Tag name state状态,然后就匹配到了空格
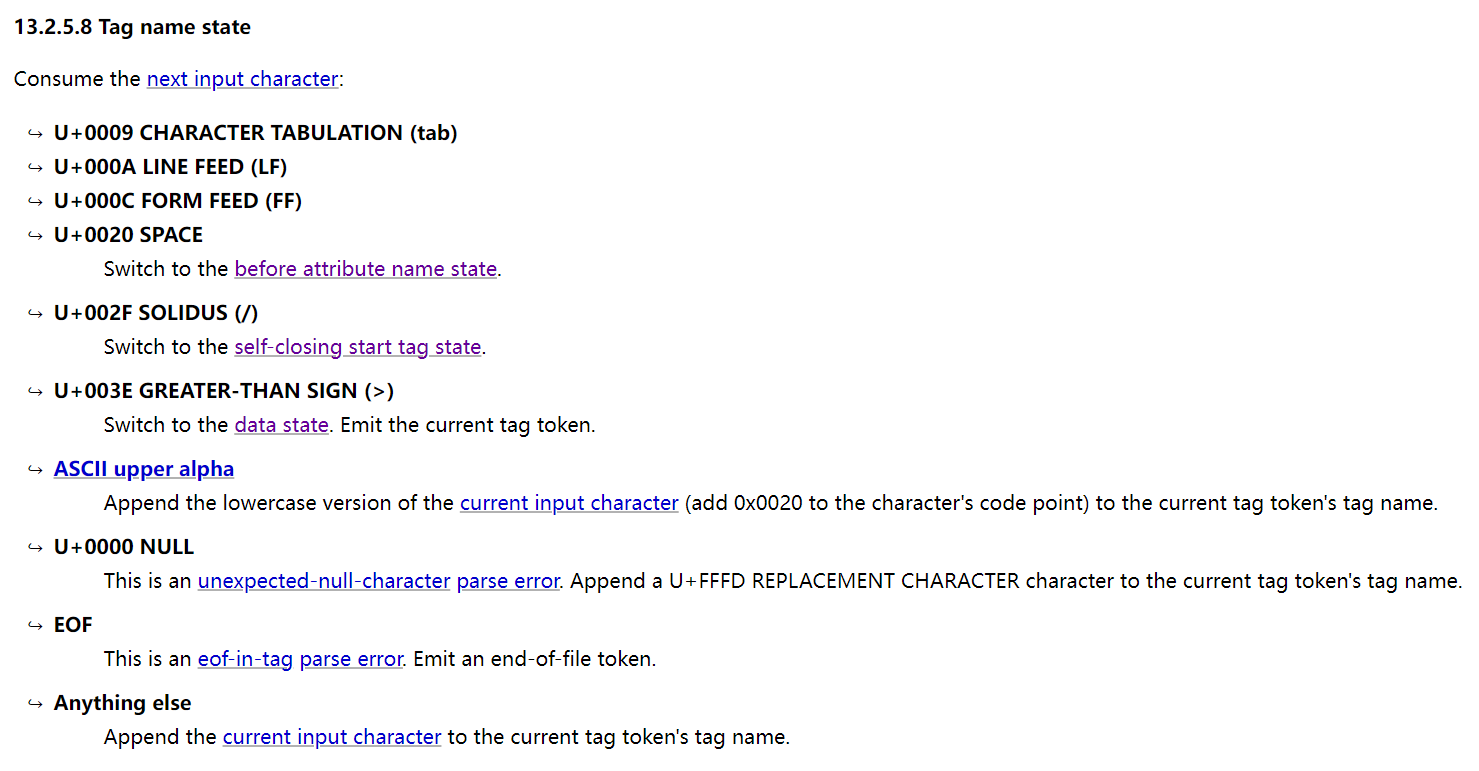
进入下一个状态before attribute name state,该状态会在当前标记令牌中启动一个新属性。将该属性名称和值设置为空字符串。

进入了attribute name state状态,将匹配到的字符src作为属性名字,然后匹配到了=

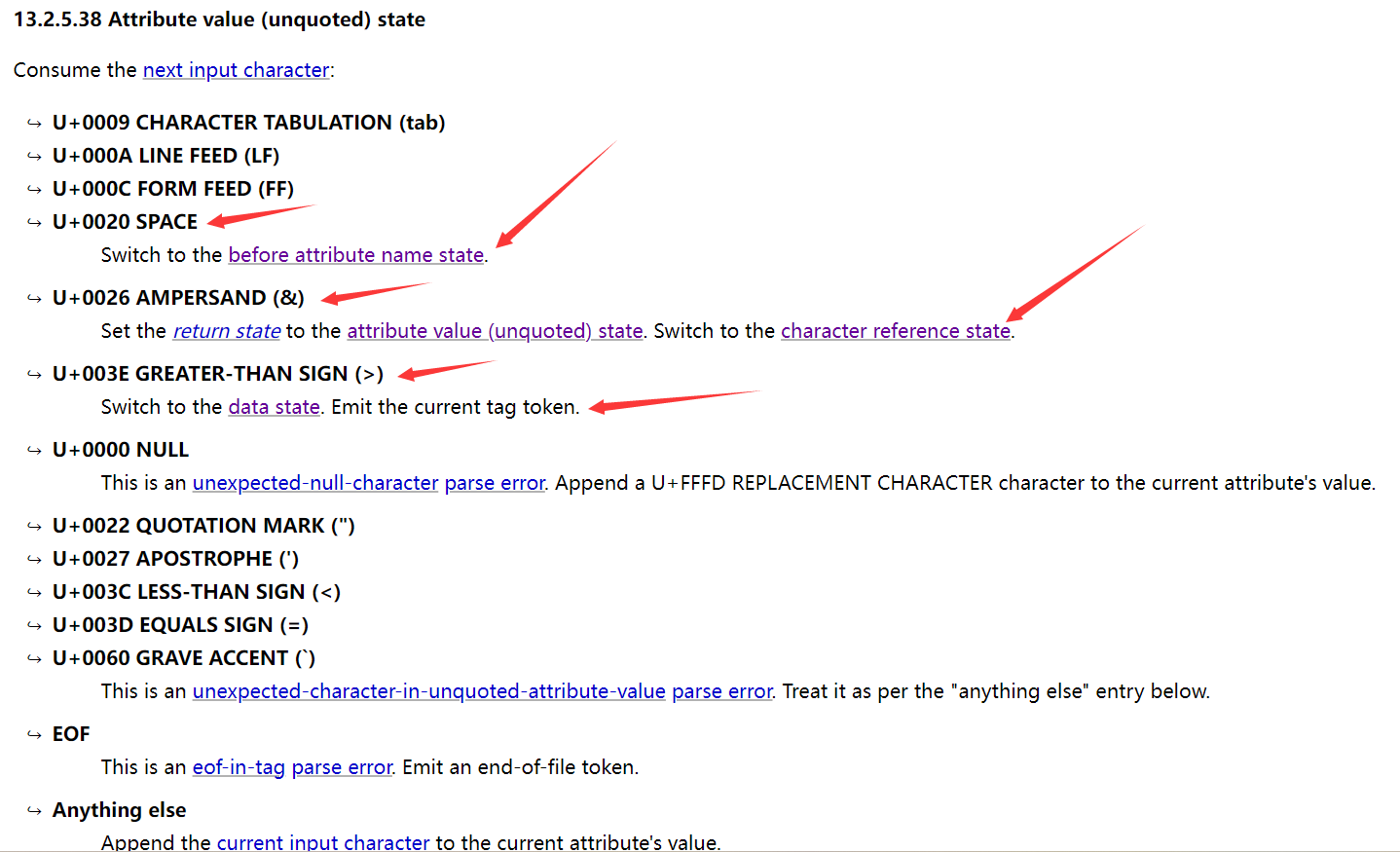
进入到before attribute value state状态,之后进入到attribute value (unquoted) state状态,因为这里属性值没有用引号包裹,否则会进入对应引号包裹的状态。

在attribute value (unquoted) state中会识别到属性值,如果遇到&字符,会进入字符引用状态,然后对html编码的内容进行解码。
大概的解析内容就是这样,在检测标签名字的时候如果输入的是大写字母则解析引擎会自动将其转变为小写。
浏览器解码顺序
在对标签属性值进行解析时遇到&字符时,会对之后的html引用进行解码操作,如果属性值输出可控的话,就可以构造恶意XSS代码执行。
1 | javascript:alert('luc1fer') |
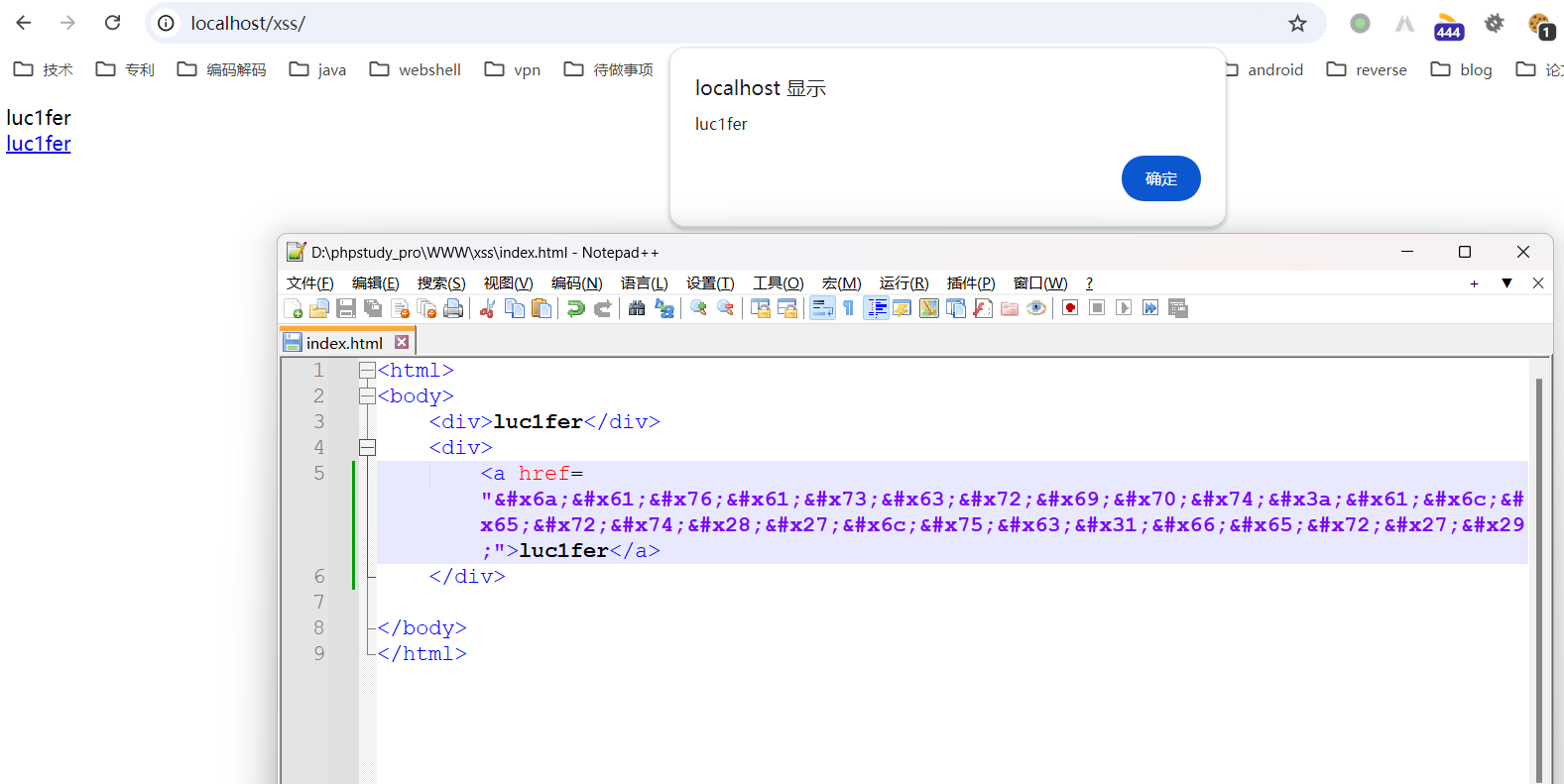
解析html标签过程中遇到<script>标签,则暂停HTML标签解析,控制权转交给JavaScript引擎,执行完后继续解析html,js可以对DOM进行修改。其实在javascript:之后的内容也会交给JavaScript引擎进行解析了,包括一些onclick、onload、onerror等事件,JavaScript引擎有一个特点,会对unicode编码的内容进行解码,但是对一些控制字符解码后会变成字面量而不具备它应有的作用,例如括号、单双引号等。
1 | <a href="javascript:\u0061\u006c\u0065\u0072\u0074('luc1fer')">luc1fer</a> |
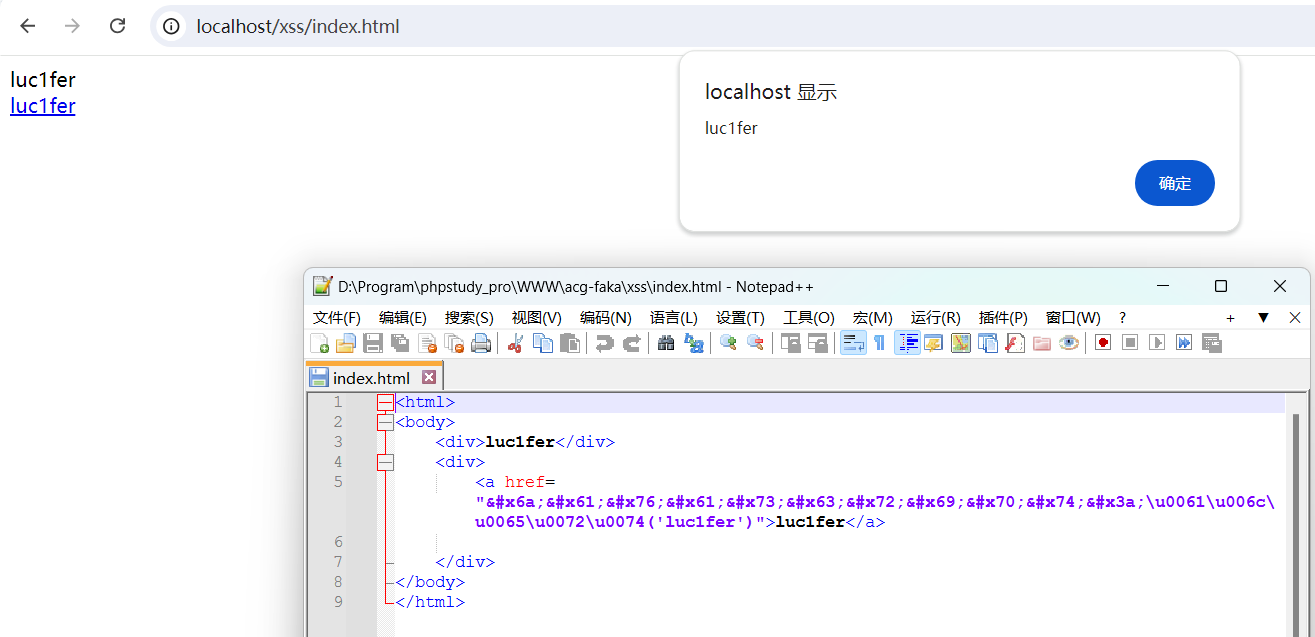
可以看出成功对unicode进行解码,如果对括号编码呢?
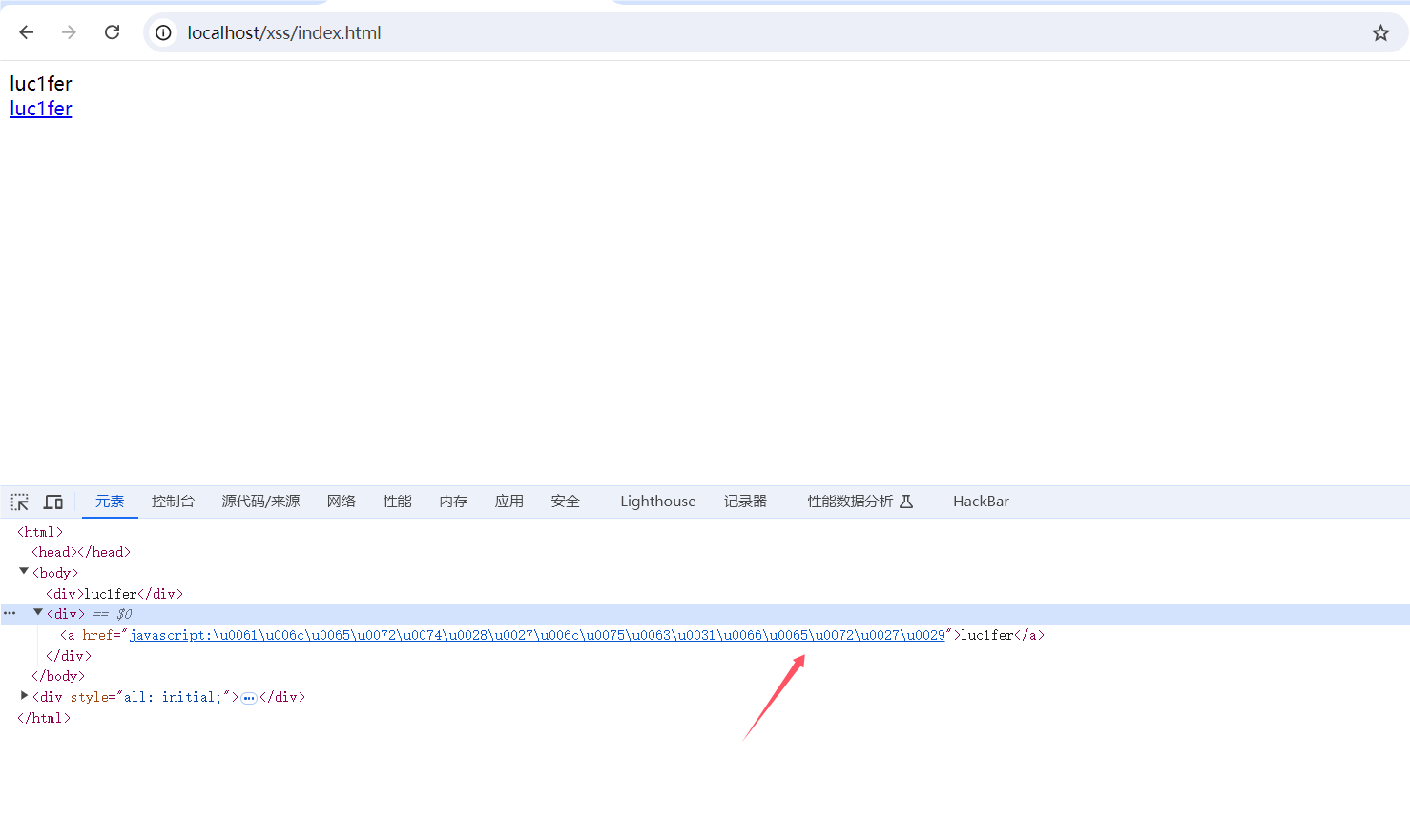
点击之后没有任何反应,所以对一些控制字符进行编码之后便会失去原本的作用。
在href属性中其实还涉及到URL解码,而且URL解码会在JS引擎之前工作,URL解码了括号和luc1fer字符之后,JS引擎才开始工作。
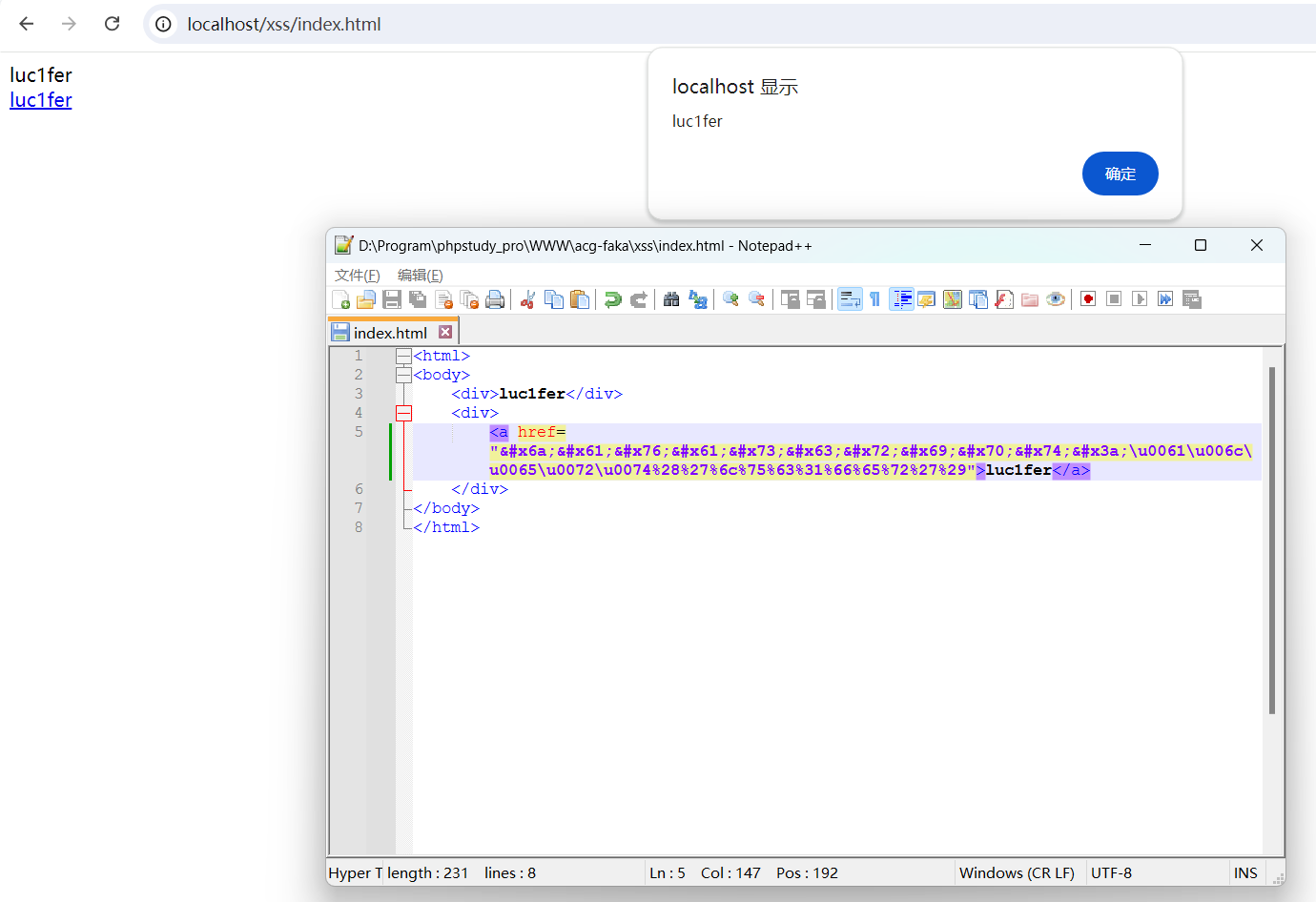
是不是可以全部用URL编码?
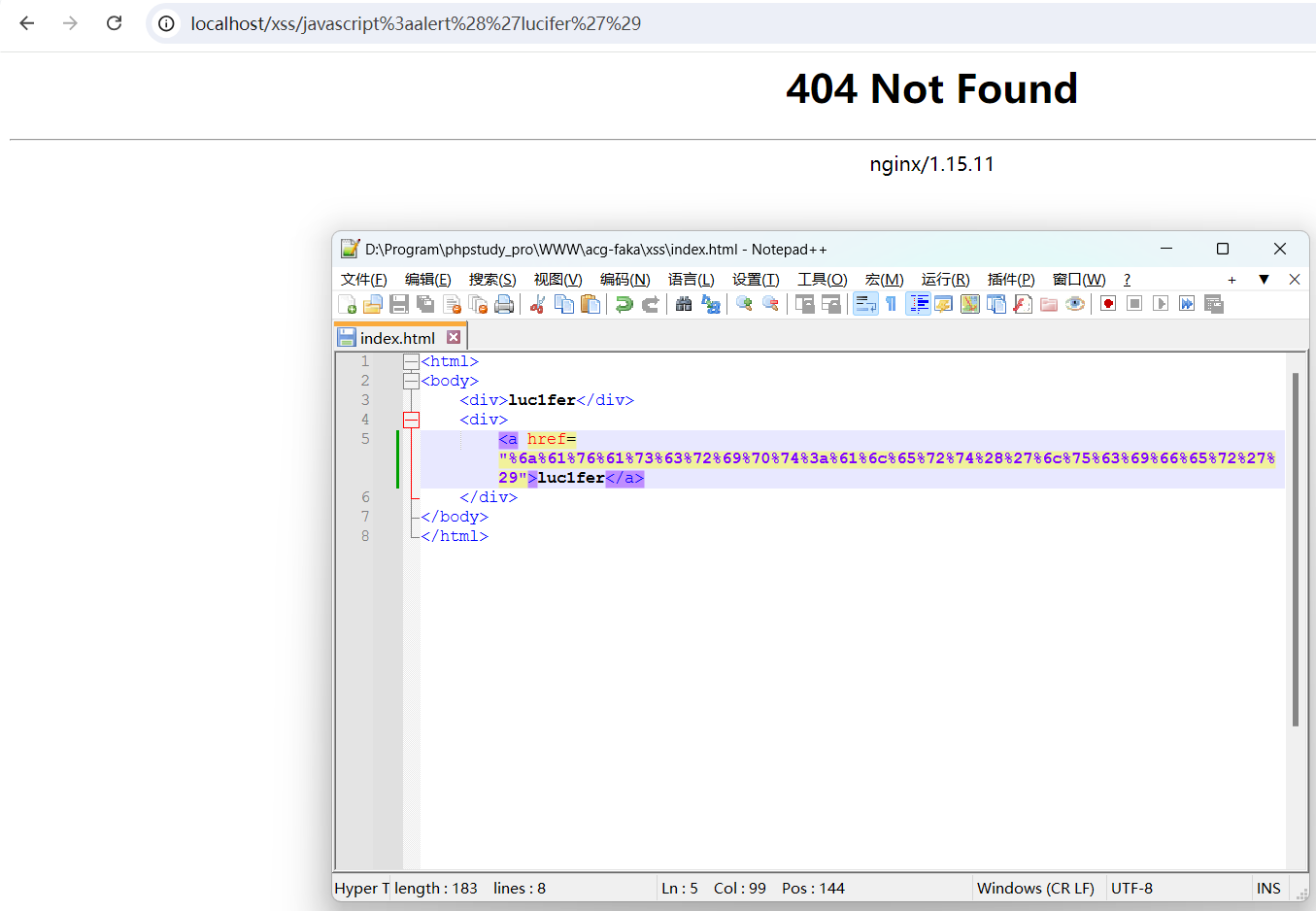
也是不行的,点击之后会直接将字符串拼接到当前域名后进行访问,说明没有解析到javascript协议,URL解析只能识别ASCII字符,不能用url编码后的字符,换句话说javascript:这几个字符至少在URL解析阶段必须是ASCII字符,所以这几个字符要编码只能用HTML实体编码,当然也可以全部用HTML实体编码。
上面讲的都是一些编码问题,下面介绍一些其他的技巧。
空格绕过
在一些特定的位置可以用/去替换空格,例如:
1 | <svg/onload=alert(1)> |
大小写绕过
1 | <SCriPt>alert(1)</SCriPt> |
总结
还有很多还没遇到,等遇到的时候再来补充。




